ARM 汇编
在 Cortex-M 启动文件 中,我们简略的介绍了 ARM 汇编的几个重要的语法。本章将会对 ARM 汇编进行详细的描述。
简介
Intel 系列 CPU 是 CISC(Complex Instruction Set Computing)复杂指令集处理器,拥有更加庞大、丰富的指令集,以及更加复杂的操作和寻址方式,寄存器更少;ARM 是 RISC(Reduced Instruction Set Computing)精简指令集处理器,寄存器数量多,指令集简单,基于寄存器架构,使用 Load/Store 结构访问存储器。
RISC-V 和 Mips 也是 RISC 架构的。
RISC 相对于 CISC 来说力图各 Opcode 的长度相等。最开始时,其所有指令长度都是 4 个字节。这也是在 ARM 链接文件 中段地址定义强调 4 字节对齐的意义。RISC 可以更快的被执行,减少了每一条指令占用 CPU 的时钟周期。比如,在 CISC 中,可以用 MULT A,B 一条指令完成硬件底层的取值、乘法、存回;在 RISC 中,则需要通过基础动作 LOAD 、PROD、STORE 等,结合寄存器中转来实现。
ARM 指令集又分为不同的版本:ARM 系列和 Thumb 系列。ARM 指令集是最初的 32 位指令集,每条指令固定位 32 bit。其性能强劲但是代码密度低,占用空间大。Thumb 是为了节省成本的产物,其为 16 位的指令集,但是性能略差。
Thumb-2 是 16 位和 32 位的混合体,处理器可以根据需要自动切换指令长度;ARM 64(AArch 64)是随着 ARM v8 架构引入的全新 64 位指令集。其重新设计了指令集,为 64 位的。其和之前的 32 位架构分离,但是可以通过兼容模式运行 32 位程序。
指令集本质上是一套规范,定义了处理器可以执行的操作和二进制编码形式,使得遵循统一指令集的的程序可以在不同 CPU 上保持兼容。汇编语言是指令集的可读形式,用助记符和符号表示机器指令。指令集链接了架构和硬件实现。架构定义了整体设计和寄存器、异常、内存模型等规则,指令集把这些规则具体化为可执行操作,CPU 按照指令集规范去执行逻辑。
ARM 架构同样作为一套规范,规定了处理器设计。CPU 按照架构实现硬件逻辑,从而实现对指令集的支持。ARM 先后提出了 ARM v4 - ARM v9 架构。ARM v4 支持基本的 ARM 指令和 Thumb 指令(v4T),知道 ARM v7 分为 A/R/M 三个架构,分别表示 Application、Real-time、Microcontroller,针对 Cortex-A、Cortex-R、Cortex-M 三个处理器。ARM v7 支持 Thumb-2 指令集。ARM v8 引入了 64 位支持(aarch 64),ARM v9 在安全性、机器学习上进行优化。Cortex 系列是 ARM 架构的具体 CPU 核实现。
关于架构、CPU 和指令集的关系。架构本身在定义行为,其不关注内部电路的实现,只要求外部表现一致。CPU 则是这个契约的具体硬件实现。而指令集是这个行为对外暴露的操作的集合。即:指令集是规定的用于操作的接口,CPU 需要能够提供这些接口。而架构规定了这些接口满足的语义规则和约束条件,确保不同厂商实现的 CPU 在执行同一指令集时得到一致的行为结果。
下表表示 ARM 架构和处理器之间的部分对应关系。

数据类型
ARM 中数据可以分为有符号和无符号两种。按照存储空间可以分为字、半字、字节。一个字节 8 位,一个半字 16 位,一个字 32 位。如下图所示。
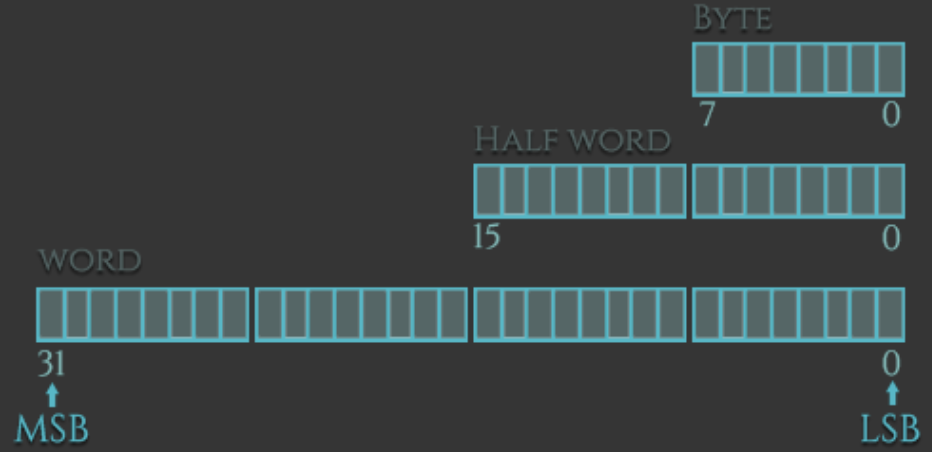
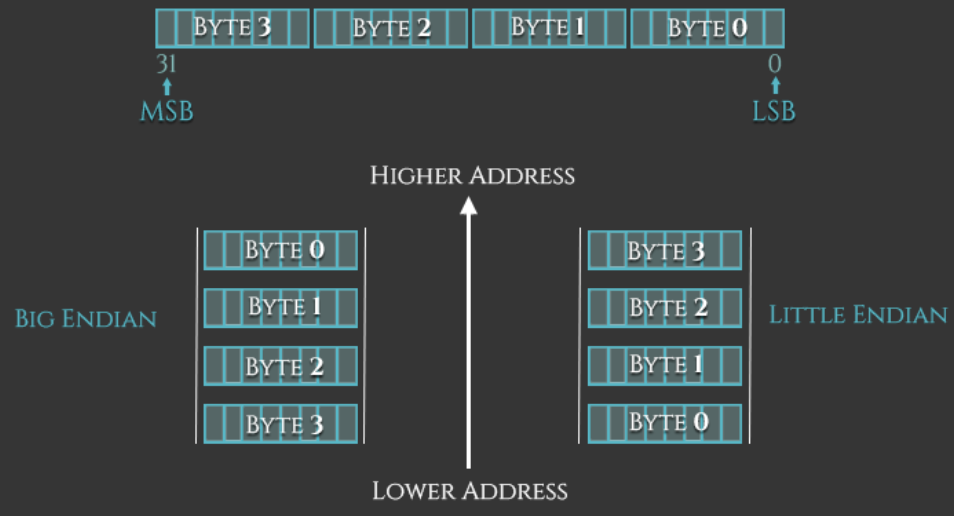
内存中的字节序有两种,小端(Little-Endian,LE)和大端(Big-Endian,BE)。x86 采用LE,ARM 在 v3 之前采用 BE,之后可以设置切换,在 CPSR(程序状态寄存器)的第九位 E(Endian)控制。
ARM 寄存器
ARM 寄存器的数量取决于 ARM 架构版本。通常,除了 ARM v6-M 和 ARM v7-M 之外,有 30 个 32 位的通用寄存器。无论在什么模式下,都有可以访问到的寄存器 R0-R15,其中前 12 个位通用寄存器,后四个是具有特殊用途的。如下图所示。
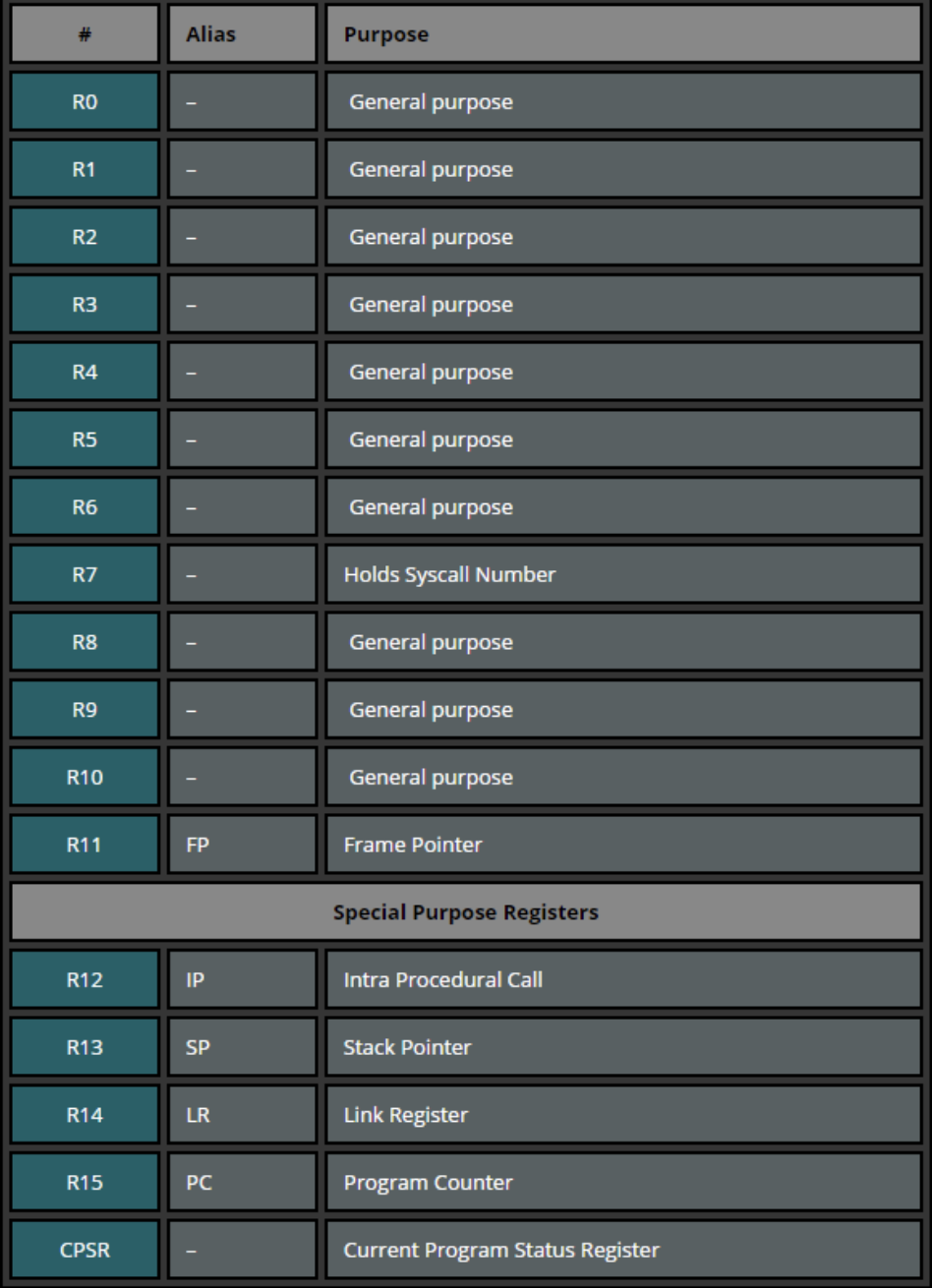
R0 - R12 通常存放在运算过程中产生的临时数据等。ARM 架构的调用约定中规定,参数的前 4 个存储在 R0 - R3 中,之后的存储在栈中。在图中,R11(FP)用于存储系统函数调用值,也就是函数的栈帧,SP(R13)用于存储栈顶,LR(R14)用于存储函数的返回地址,PC(R15)在 ARM 模式下存储当前指令地址+8、Thumb 存储当前地址+4、x86 存储下一条将要执行的指令地址,CPSR 用于存储当前程序的状态。具体用途如下。

其中 N/Z/C/V 位用于表示当前汇编行的计算结果状态。N 表示计算结果为负数,Z 为计算结果为 0,C 为计算结果进位,V 表示计算结果溢出。
ARM 指令集格式
ARM 指令集的基本格式为:
MNEMONIC{S} {condition} {Rd}, Operand1, Operand2
其中:
MNEMONIC为指令集的短名字,即助记符,比如MOV、LDR等;{S}为一个可选的后缀。如果加了 S 后缀,则 CPSR 寄存器中相关的位被更新为操作结果;{condition}为执行指令需要满足的条件;{Rd}为存储计算结果的寄存器;Operand1为第一操作数,可以为寄存器也可以是立即数;Operand2为第二操作数(可选),可以是立即数或具有可选移位的寄存器。
ARM 寻址方式
立即寻址
mov r0, #1234
相当于 r0 = #1234。由 # 开头表示以 16 进制时以 0x 开头。
寄存器寻址
mov r0, r1
执行后, r0 = r1。
寄存器移位寻址
寄存器移位寻址支持以下寻址操作:
- LSL:逻辑左移,移位后寄存器空出的低位补 0;
- LSR:逻辑右移,移位后寄存器空出的高位补 0;
- ASR:算术右移,移位时符号位不变。如果源操作数为整数,则移位后空出的高位补 0,否则补 1;
- ROR:循环右移,移位后移出的低位填入空出的高位;
- RRX:带拓展的循环右移,操作数右移一位用 CPSR 寄存器中 C 位的值填充。
如,mov r0, r1, lsl #2 相当于 r0 = r1<<2 = r1*4。
寄存器间接寻址
ldr r0, [r1]
相当于 r0 = *r1。
基址寻址
ldr r0, [r1, #-4]
相当于 r0 = *(r1-4)。
多寄存器寻址
ldmia r0, {r1, r2, r3, r4}
LDM 是数据加载指令,后缀 IA 表示执行完加载操作后,R0 寄存器的值自增。上面的汇编相当于r1 = [r0], r2 = [r0+#4], r3 = [r0+#8], r4 = [r0+#12]。
堆栈寻址
需要特定的指令完成:
stmfd sp!, {r1~r7, lr} 表示将 r1~r7, lr 压栈,多用于保存子程序现场;
ldmfd sp!, {r1~r7, lr} 表示将 r1~r7, lr 出栈。
块拷贝寻址
可以实现连续地址数据从寄存器的某一位置拷贝到另一位置。如:
ldmia r0!, {r1-r3} 表示从 r0 指向的地址的值放到 r1~r3 中;
stmia r0!, {r1-r3 表示将 r1~r3 的值取出,放到 r0 指向的位置。
相对寻址
如:
bl .lc0
; ...
.lc0:
; ...
bl 将会直接跳到 .lc0 处。
ARM 指令
ARM 汇编指令包括存储加载类指令集,数据处理类指令集,分支跳转类指令集,程序状态寄存器访问指令以及协处理器类指令集等。
存储加载类指令
由于 ARM 处理器采用了统一编址技术,因而对外围 I/O,程序数据的访问都要通过加载/存储(Load/Store)指令来进行。ARM 的加载/存储指令(LDR,STR)可以实现字、半字、无符号、有符号字节操作。
批量加载/存储(LDM,STM)可以实现一条指令加载存储多个存储器的内容,加载效率大为提高,一般用来传递参数和复制数据。
ARM 采用 RISC 架构,CPU 本身不能直接读取内存,而需要先将内存中内容加载入 CPU 中通用寄存器中才能被 CPU 处理。ldr/str 组合用来实现 ARM CPU 和内存数据交换。
LDR用于从内存中读取数据加载到内存中。如LDR R0, [R1]表示将 R1 所指向的存储单元的内容加载到 R0 寄存器中。STR用于将寄存器中的数据保存到内存单元。如STR R0, [R1]表示将 R0 寄存器里面的数据保存到 R1 所指向的内存中。LDM用于将一块连续的内存单元的数据加载多个寄存器中。STM用于将多个寄存器的数据保存到一块连续的内存单元之中。
具体示例如下:
LDR R0, =num ; R0 = num 的地址
LDR R1, [R0] ; R1 = *num,读取内存值
ADD R1, R1, #5 ; R1 = R1 + 5
STR R1, [R0] ; 将 R1 写回 num
数据处理类指令
该类指令包括数据传送指令 mov,算是逻辑运算符 add,sub,bic,orr 等,比较指令 cmp,tst 等。
MOV R0, #3 ; R0 = 3
ADD R1, R0, #5 ; R1 = R0 + 5 = 8
SUB R2, R1, #2 ; R2 = R1 - 2 = 6
AND R3, R2, #0x0F ; R3 = R2 & 0x0F = 6
ORR R4, R3, #0xF0 ; R4 = R3 | 0xF0 = 0xF6
EOR R5, R4, R3 ; R5 = R4 ^ R3 = 0xF0
CMP R5, #0xF0 ; 比较 R5 与 0xF0, 设置 N, Z, C, V 标志
TST R4, #0x0F ; 按位与测试 R4 & 0x0F, 设置标志位
若在指令后添加 S,表示其按照前文中的描述更改 CPSR 寄存器的值。
分支和跳转命令
b:无条件跳转bl:调用子程序后返回,保存返回地址到 LR 寄存器。bx:跳转到寄存器的指定地址beq/blt/bgt/...:分支指令,根据标志位跳转。其根据 CPSR 中的四个位确定是否跳转。具体条换规则如下。条件码为 B 后面的字符。
| 条件码 | 全称 | 条件 |
|---|---|---|
| EQ | Equal | Z = 1 |
| NE | Not Equal | Z = 0 |
| GT | Greater Than | Z = 0 且 N = V |
| LT | Less Than | N ≠ V |
| GE | Greater or Equal | N = V |
| LE | Less or Equal | Z = 1 或 N ≠ V |
| CS/HS | Carry Set / Unsigned Higher or Same | C = 1 |
| CC/LO | Carry Clear / Unsigned Lower | C = 0 |
| 可能的示例如下: |
CMP R0, #0
BEQ zero_label
B end
zero_label:
MOV R1, #1
end:
伪指令
伪指令是汇编器用来控制汇编过程和程序布局的命令,它们不生成机器码,只是告诉汇编器如何组织代码和数据。
段定义指令
用于定义代码段、数据段等:
| 指令 | 功能 | 示例 |
|---|---|---|
.text |
定义代码段,汇编器把之后的内容视为程序指令 | .text |
.data |
定义可读写数据段 | .data |
.bss |
定义未初始化的全局/静态数据 | .bss |
.rodata |
定义只读数据段(通常用于字符串常量) | .rodata |
示例:
.text
_start:
MOV R0, #0 ; 代码段里的指令
B end
.data
num: .word 10 ; 定义数据段变量 num = 10
.bss
buffer: .skip 64 ; 预留 64 字节空间,未初始化
数据定义指令
用于定义变量、数组、常量等:
| 指令 | 功能 | 示例 |
|---|---|---|
.word |
定义 32 位数据 | num: .word 10 |
.byte |
定义 8 位数据 | flag: .byte 0xFF |
.half |
定义 16 位数据 | value: .half 0x1234 |
.space / .skip |
分配未初始化空间 | .space 16 |
.ascii |
定义不带结束符的字符串 | .ascii "Hello" |
.asciz / .string |
定义以 \0 结尾的字符串 |
.asciz "Hello\0" |
示例:
.data
value: .word 100 ; 32位整数
flag: .byte 0xFF ; 8位
name: .asciz "ARM" ; C风格字符串,结尾自动加 '\0'
array: .space 16 ; 预留16字节空间
符号和全局指令
| 指令 | 功能 | 示例 |
|---|---|---|
.global |
声明符号为全局,可被其他文件访问 | .global _start |
.extern |
声明外部符号,由其他文件提供 | .extern printf |
.equ / .set |
定义常量符号 | BUFFER_SIZE .equ 64 |
示例:
.global _start ; 入口符号可被链接器识别
BUFFER_SIZE .equ 64 ; 定义常量
汇编控制器指令
| 指令 | 功能 | 示例 |
|---|---|---|
.align |
对齐地址(通常按 2^n 字节对齐) | .align 4 |
.org |
设置当前位置计数器(PC)到指定地址 | .org 0x1000 |
.end |
汇编文件结束标记 | .end |
| 示例: |
.text
.align 4 ; 4字节对齐
_start:
MOV R0, #0
.org 0x2000 ; 强制下一条数据在 0x2000 地址开始
data_at_0x2000: .word 0x1234
在以上的汇编指令之外,还有基于这些基础指令的拓展,比如不同的数据 Load/Store 方式、移位方式等。在此不再赘述。
Hello, ARM
本节通过一个实例介绍 ARM 汇编是如何工作的。
首先,准备好 ARM 64 的编译器,如 clang,这是 macOS 中自带的编译器。新建一个文件,名为 main.S。
编写以下内容:
.text
.file "main.c"
.global main
.p2align 2
.text 表示进入代码段,下面的描述为程序指令;.file 告诉汇编器/调试器这段汇编来自哪个文件,这里伪装为 main.c。他不影响生成的机器码,是给 gdb 这样的调试器使用的。global 定义了一个符号:main 为全局符号。这意味着链接器可以在其他文件中访问 main,并且他是程序入口点。对应 C 程序中的 int main()。p2align n 表示按照 的方式对齐,这里为对齐 4 字节。
接下来可以书写 main 函数的部分:
.type main,@function
main: // @main
// %bb.0:
sub sp, sp, #32 // =32
stp x29, x30, [sp, #16] // 16-byte Folded Spill
add x29, sp, #16 // =16
mov w8, wzr
stur wzr, [x29, #-4]
adrp x0, .L.str
add x0, x0, :lo12:.L.str
str w8, [sp, #8] // 4-byte Folded Spill
bl printf
ldr w8, [sp, #8] // 4-byte Folded Reload
mov w0, w8
ldp x29, x30, [sp, #16] // 16-byte Folded Reload
add sp, sp, #32 // =32
ret
我们利用 .type 定义了标签 main 为一个函数 @function。其主要命令的介绍如下。
| 汇编指令 | C 对应 | 作用说明 |
|---|---|---|
.type main,@function |
int main() |
声明 main 是函数 |
main: |
int main() |
函数入口 |
sub sp, sp, #32 |
自动管理栈 | 为局部变量分配 32 字节栈空间 |
stp x29, x30, [sp, #16] |
保存帧指针和返回地址 | 保存调用现场(函数栈帧) |
add x29, sp, #16 |
设置帧指针 | x29 指向当前栈帧基址 |
mov w8, wzr |
w8 = 0 |
将 0 存到 w8 寄存器 |
stur wzr, [x29, #-4] |
初始化局部变量 | 栈上的局部变量置零 |
adrp x0, .L.str + add x0, x0, :lo12:.L.str |
获取字符串地址 | printf 参数地址 |
str w8, [sp, #8] |
保存 w8 到栈 | printf 参数传递 |
bl printf |
printf(...) |
调用 printf |
ldr w8, [sp, #8] |
恢复 w8 | printf 后获取返回值或原值 |
mov w0, w8 |
设置返回值寄存器 | main 的返回值放到 w0 |
ldp x29, x30, [sp, #16] |
恢复帧指针和返回地址 | 函数返回前恢复现场 |
add sp, sp, #32 |
回收栈空间 | 清理栈帧 |
ret |
return |
返回调用者 |